Enterprise AI spending on LLM APIs doubled to $8.4 billion globally last year. Most of that traffic flows through direct point-to-point integrations: application code calling OpenAI, Anthropic, or Google endpoints with provider-specific SDKs. That works fine for a prototype. It falls apart the moment you depend on AI for anything that matters in the real world.
I’m building VIA, an AI platform for product development from ideation to product-market fit. One of the first architectural decisions I had to make wasn’t which model to use. It was how to decouple the platform from model providers entirely. The answer is an LLM Gateway: a centralized abstraction layer that sits between applications and model providers:
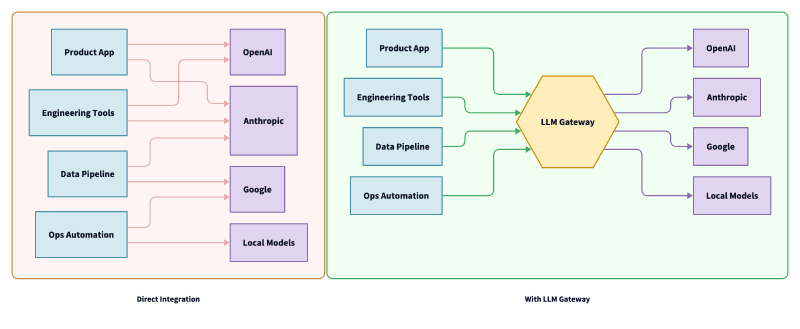
This isn’t a new concept. API gateways are standard infrastructure for microservices. But LLM traffic does introduce problems that generic API gateways can’t solve: payload translation between incompatible schemas, real-time streaming protocol conversion, tool-calling orchestration for autonomous agents, and cost governance at token level.
Here’s what the gateway layer must do, and why each capability is non-negotiable at scale.
The Problem: Direct Integration Doesn’t Scale#
Picture a typical enterprise AI deployment six months in: The product team uses GPT-5 for content generation. Engineering runs Codex for code reviews. The data team uses Claude for analysis. The ops team experiments with local Llama models for cost-sensitive batch work.
Each integration has its own SDK, its own authentication, its own error handling, its own retry logic. Nobody knows the total token spend across the organization. When OpenAI has an outage, the product goes dark, and nobody finds out until customers complain.
This is the same integration spaghetti that drove the adoption of API gateways in the microservices era. The difference is that LLM traffic is harder to proxy. You can’t just forward HTTP requests. An LLM Gateway needs to understand and transform payloads in transit.
Capability 1: Unified API — One Interface, Many Providers#
The industry has coalesced around OpenAI’s /v1/chat/completions schema as the defacto standard. An LLM Gateway exposes this single interface to all client applications and translates requests to each provider’s native format behind the scenes.
This means developers write against one API. Switching from GPT-5 to Claude Opus for a specific workload is a routing configuration change, not a code change. Adding a new provider doesn’t touch application code at all.
The practical impact: your applications are decoupled from provider choices. This is not about theoretical cleanliness, but about operational survival. Provider pricing changes, capability shifts, and outages become infrastructure concerns, not application emergencies.
Capability 2: Fallback Routing — Surviving Provider Outages#
Dependence on a single LLM Provider is a single point of failure. When that provider has an outage, every dependent application goes down with it.
An LLM Gateway solves this with fallback chains: ordered lists of alternative providers that activate automatically. If the primary provider fails, hits a rate limit or exceeds a latency threshold, the gateway tries the next one. The client application never sees the failure:
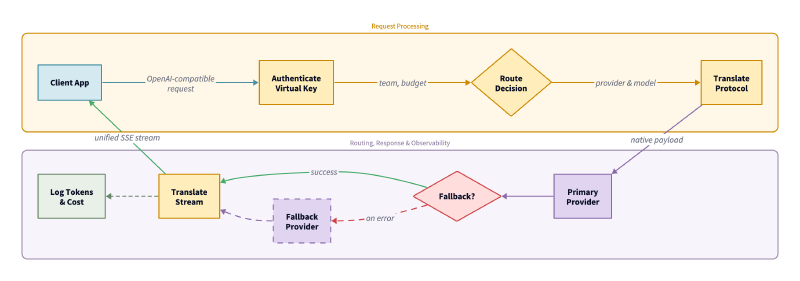
Beyond static fallbacks, advanced LLM Gateways support adaptive load balancing: distributing requests across API keys, deployments, or regions based on real-time health metrics. Some go even further with intent-based routing: evaluating prompt complexity and directing simple queries to cheap, fast models while reserving frontier models for complex reasoning tasks.
This enables cost optimization without sacrificing output quality where it matters.
Capability 3: Protocol Translation — The Hard Part#
This is where generic API gateways fail completely. LLM Providers implement the same concepts using fundamentally different JSON schemas. Proxying basic text is trivial. Translating tool calling payloads between providers is not.
Consider the structural differences between OpenAI and Anthropic:
- System prompts: OpenAI allows system instructions as a message in the
messagesarray ({"role": "system", "content": "..."}). Anthropic requires the system prompt as a top-levelsystemfield, completely separate from the conversation. - Tool results: OpenAI uses a dedicated
toolrole for tool execution results. Anthropic maps tool results into theuserrole with a specific content structure. - Required parameters: OpenAI treats
max_tokensas optional. Anthropic requires it. The gateway must inject defaults for missing fields as needed.
Every one of these mismatches causes silent failures or broken agent loops if the translation isn’t precise. The gateway must dissect incoming payloads and remap fields exactly, not approximately!
Capability 4: Streaming Preservation — Don’t Buffer the Response#
Interactive applications and CLI tools expect real-time streaming. The gateway must translate streaming protocols on the fly without buffering the entire response, as this would destroy the user experience.
This is trickier than it sounds. Providers use different Server-Sent Event (SSE) formats. Anthropic emits structured multi-stage events: message_start, content_block_delta, message_delta. Translating these to OpenAI-compatible chat.completion.chunk objects requires the gateway to maintain state across the stream: capturing message IDs from start events, repackaging text deltas, and mapping terminal events to finish_reason values.
Continuous translation must happen with near-zero latency. Any buffering or processing delay breaks the fluid experience that makes streaming valuable in the first place.
Capability 5: Data Sovereignty — Keep Sensitive Data In-House#
This is the capability that turns an LLM Gateway from a convenience into a compliance requirement.
Roughly 40% of files uploaded to generative AI tools contain PII, credentials, or confidential data. For organizations handling such data (e.g. healthcare records, financial information, proprietary source code, etc.), sending prompts to public provider endpoints is unacceptable.
The architecture must support routing to locally hosted inference endpoints (Ollama, vLLM, etc.) running on internal GPU clusters. The LLM Gateway itself must be deployable entirely on-premises or within a private VPC, operating air-gapped from the public internet if required.
In this setup, the LLM Gateway manages routing between internal applications and internal GPU infrastructure. Sensitive data never leaves the network. Public providers remain available for non-sensitive workloads, giving you the best of both worlds. Cost-effective cloud models for general tasks, sovereign infrastructure for regulated data.
Capability 6: Cost Governance — Know What You’re Spending#
Unmanaged multi-provider LLM usage leads to opaque, uncontrolled spending surprisingly fast. An LLM Gateway provides financial governance through virtual keys: distinct API keys tied to teams, projects, or cost centers.
As requests flow through the gateway, it calculates costs in real-time based on granular token metrics: prompt tokens, completion tokens, cache reads, cache writes. This telemetry can feed into existing observability stacks alongside the rest of your infrastructure monitoring.
The practical result: you can answer “how much did team X spend on AI this month?” without scraping individual provider dashboards. You can set budget limits per team. You can identify which workflows burn tokens more efficiently than others. With such a centralized view, cost optimization is no longer guesswork.
The Emerging Capability: MCP Control Plane#
One capability is still emerging but worth mentioning: A control plane for Model Context Protocol (MCP) based external tools and data sources.
As AI moves from isolated text generation toward autonomous agents that interact with databases, APIs, and execution environments, LLM Gateways become the natural control plane.
Instead of every application managing its own tool connections, the LLM Gateway centralizes authentication, enforces access control (which keys can call which tools), and maintains audit trails of agentic actions.
This matters because autonomous agents acting within a corporate network require the same governance as any other system integration: authentication, authorization, and logging. The LLM Gateway is the right place to enforce it.
What This Means in Practice#
An LLM gateway is not a nice-to-have. It’s the architectural layer that makes enterprise AI deployable, governable, and resilient. Without it, you’re building on direct provider dependencies that will break at the worst possible moment.
The six capabilities form a hierarchy:
- Unified API decouples applications from providers
- Fallback routing facilitates surviving outages and optimizing costs
- Protocol translation makes multi-provider routing actually work
- Streaming preservation maintains real-time user experience
- Data sovereignty meets compliance requirements
- Cost governance controls spending across the organization
If you’re running AI in production with direct provider integrations, you’ve most likely already felt some of these pains. The LLM Gateway addresses all of them in a single architectural layer.
I’m currently evaluating specific gateway implementations for my own platform. In a follow-up post, I’ll share which three made my shortlist, the selection criteria that mattered most, and what I’m looking for in hands-on testing.